아래는 10편(최종편) 전체 본문 확장판 초안입니다.
이 편은 연재의 결론 + 도입 판단 가이드 역할을 하도록 구성했습니다.
- “Parca가 좋은가?”가 아니라 “누가 써야 하는가”
- 기술적 적합성 + 조직적 적합성
- 도입해도 실패하는 경우까지 포함
- CTO / SRE / 플랫폼 팀이 읽어도 설득되는 구조
Parca는 누구에게 필요한 도구인가
도입 판단 가이드 & 연재 정리
이 연재를 여기까지 읽었다면,
이제 질문은 단순해진다.
“Parca는 쓸 수 있는 도구인가?” ❌
“우리에게 필요한 도구인가?” ⭕
Parca는 좋은 도구다.
하지만 모두에게 필요한 도구는 아니다.
이번 마지막 편에서는
Parca 도입 여부를 판단할 수 있도록
사람·조직·문제 유형 기준으로 정리한다.
1️⃣ Parca는 어떤 문제를 푸는 도구인가
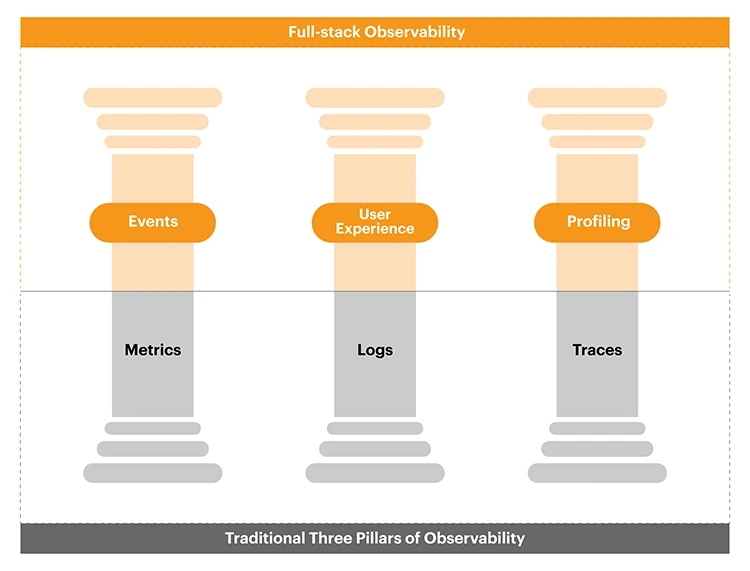

Parca가 푸는 문제는 매우 명확하다.
“CPU 시간은 정확히 어디에서 소비되는가?”
이 질문에 대한 답이 필요하지 않다면
Parca는 과분한 도구다.
Parca가 잘 푸는 질문들
- CPU 사용률은 정상인데 왜 느린가?
- 커널과 유저 코드 중 어디에서 병목이 생겼는가?
- 배포 전/후 성능이 실제로 바뀌었는가?
- 컨테이너 수 증가가 CPU 경로에 어떤 영향을 줬는가?
- APM으로 설명되지 않는 성능 저하의 원인은?
Parca가 풀지 않는 질문들
- 어떤 API가 느린가?
- 에러율이 왜 증가했는가?
- 특정 사용자 요청의 전체 흐름은?
- 비즈니스 트랜잭션은 어떻게 흘렀는가?
👉 이 질문들은 APM의 영역이다.
2️⃣ Parca가 “잘 맞는 사람들”
① 시스템 프로그래머 / 플랫폼 엔지니어


- C/C++ / Rust / Go
- 커널 함수, syscall, lock에 익숙
- “왜?”를 파고드는 성향
이들에게 Parca는:
“CPU 내부를 그대로 보여주는 현미경”
이다.
② SRE / 인프라 팀
- 장애 재현이 어려움
- 문제 발생 시 이미 지나가 있음
- 숫자 지표만으로 설명 불가
Parca는 SRE에게 이렇게 말해준다.
“문제는 이미 지나갔지만,
흔적은 남아 있다.”
③ Kubernetes / 컨테이너 플랫폼 팀

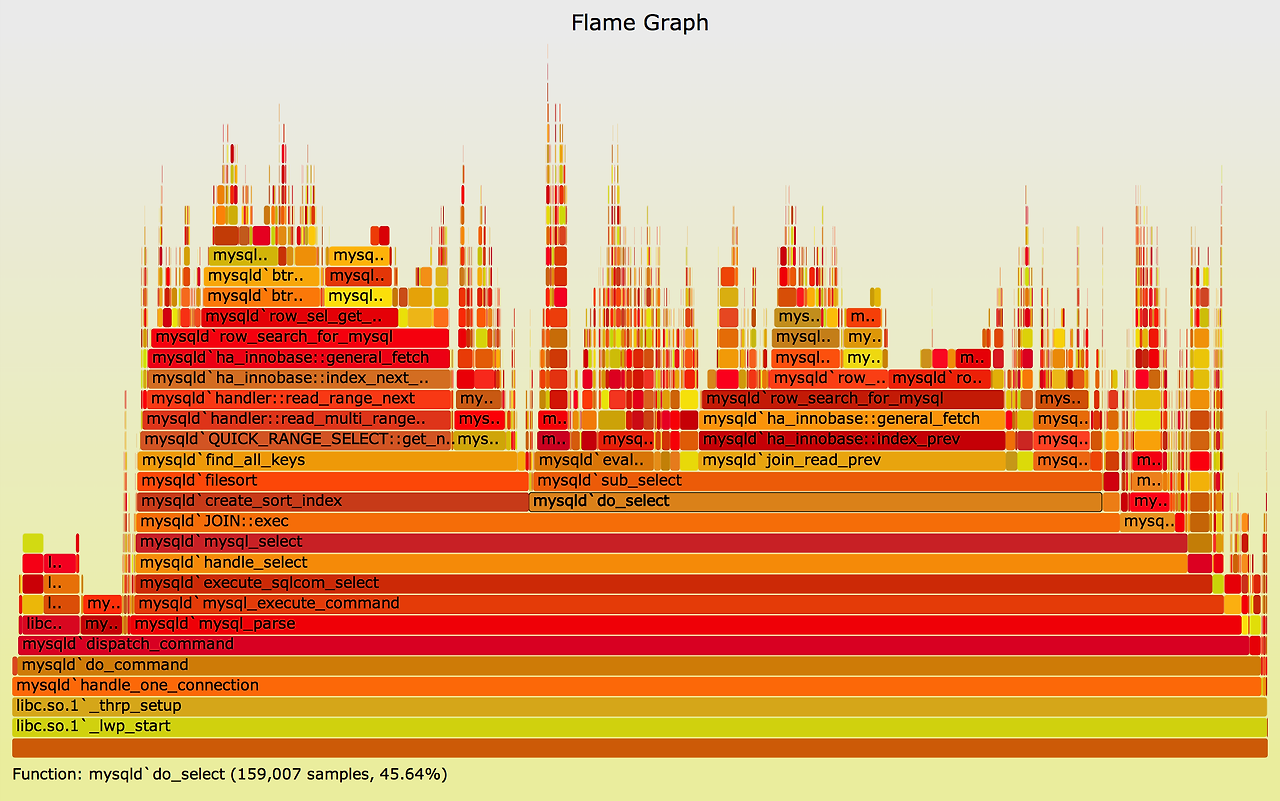
- 노드 단위 성능 분석 필요
- 컨테이너 간 간섭 문제
- cgroup / scheduling 이슈
Parca는:
- 컨테이너 추상화를 벗기고
- 실제 커널 실행 경로를 보여준다.
3️⃣ Parca가 “잘 맞지 않는 사람들”
이 부분은 솔직해야 한다.
① 애플리케이션 개발자 단독 사용
- Flamegraph 해석 경험 없음
- 커널 함수에 익숙하지 않음
- “이게 느린 건지?” 판단 어려움
이 경우 Parca는:
“멋있지만, 이해하기 어려운 그래프”
로 남을 가능성이 크다.
② APM 대체를 기대하는 조직
❌ Parca = APM
❌ Parca = Prometheus 대체
이 기대를 가지고 시작하면
도입은 거의 확실히 실패한다.
③ 규제/포렌식 목적 환경
- 모든 데이터를 빠짐없이 저장
- 특정 시점의 정확한 증거 필요
Parca는:
- 일부 샘플 손실 허용
- 통계적 정확성 기반
👉 목적이 다르다.
4️⃣ 조직 기준 도입 판단 가이드
아래 질문에 “예”가 많을수록 적합
- 성능 문제 재현이 자주 실패하는가?
- “느리다”는 말을 수치로 설명하기 어려운가?
- 커널/네이티브 코드 비중이 있는가?
- Kubernetes 환경에서 노드 병목이 의심되는가?
- APM + 메트릭만으로 부족함을 느끼는가?
3개 이상이면 도입 검토 가치 충분이다.
5️⃣ Parca의 이상적인 포지션

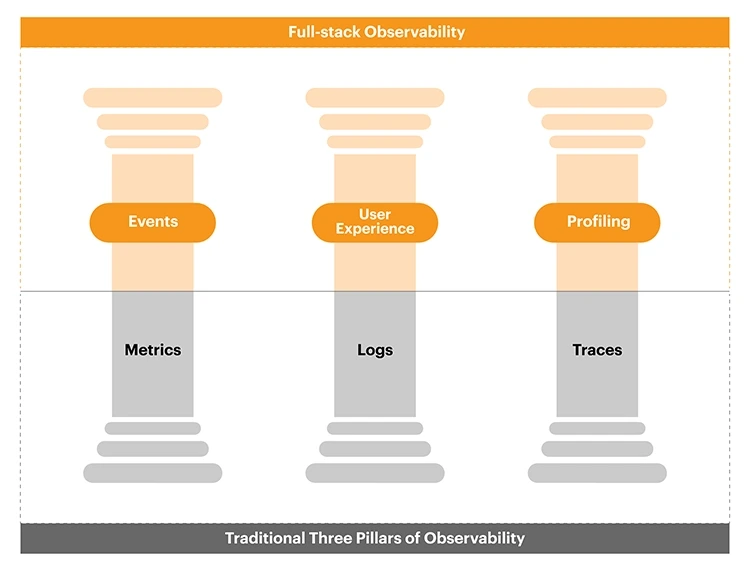
Parca는 이 위치에 있어야 한다.
Metrics → “문제가 있다”
APM → “요청은 정상이다”
Parca → “CPU는 여기서 막히고 있다”즉,
Parca는 마지막 퍼즐 조각이다.
6️⃣ PoC → 운영으로 가는 현실적인 경로
추천 도입 순서
- 비중요 노드에 agent 배포
- 낮은 샘플링 빈도로 시작
- Flamegraph 읽는 연습
- 실제 이슈 1~2건 해결
- 그 후 확대
절대 피해야 할 시작 방식
❌ 전 노드 일괄 배포
❌ “일단 깔아보자”
❌ Flamegraph 교육 없이 공개
7️⃣ Parca 연재 전체 요약 (한 페이지)
- Parca는 Continuous Profiling 도구
- Push/Pull 이분법보다 profiling 전용 구조
- eBPF + CO-RE로 운영 가능
- Flamegraph는 “정답”이 아니라 “지도”
- 컨테이너 환경에서 특히 강력
- 도입 실패 원인은 대부분 기술이 아니라 기대
8️⃣ 이 연재의 결론
Parca는 성능을 “보여주는” 도구가 아니라
성능을 “설명할 수 있게 만드는” 도구다.
- 숫자를 넘어
- 그래프를 넘어
- “왜 그런가”에 답하게 만든다
그 답이 필요하다면,
Parca는 충분히 도입할 가치가 있다.
에필로그: 언제 Parca를 배우면 좋은가
- perf를 써봤지만 답답할 때
- APM이 “정상”만 말할 때
- Kubernetes 성능이 미스터리일 때
- “느리다”는 말을 증명해야 할 때
그때가 바로
Parca를 써야 할 시점이다.
'Parca' 카테고리의 다른 글
| 9편. Parca 도입 시 현실적인 고려사항– 운영, 보안, 성능 관점 (0) | 2025.12.20 |
|---|---|
| 8편. CO-RE와 Parca – 커널 의존성 문제는 어떻게 해결되는가 (0) | 2025.12.20 |
| 7편. 컨테이너·Kubernetes 환경에서의 Parca– PID, Namespace, cgroup 관점 (0) | 2025.12.20 |
| 6편. 실전 사례 ① – CPU 사용률은 정상인데, 성능은 느린 이유 (0) | 2025.12.18 |
| 5편. Flamegraph 제대로 읽기– Parca UI 해석 가이드 (0) | 2025.12.18 |