아래는 7편 전체 본문 확장판 초안입니다.
이번 편은 Parca를 Kubernetes 환경에서 “제대로” 쓰기 위한 핵심 이론 편입니다.
- 컨테이너 환경에서 왜 profiling이 더 어려운지
- PID / Namespace / cgroup 관점에서 Parca가 무엇을 보고 있는지
- Flamegraph를 어디까지 믿어도 되는지
- 실무에서 가장 많이 헷갈리는 포인트 정리
컨테이너·Kubernetes 환경에서의 Parca
PID, Namespace, cgroup 관점
Parca를 Kubernetes 환경에 배포한 뒤
Flamegraph를 처음 보면 이런 생각이 들 수 있다.
“이게 어느 컨테이너 거지?”
“PID가 왜 이렇게 이상하지?”
“노드 커널 함수가 왜 이렇게 많이 보이지?”
이 혼란은 도구의 문제가 아니라,
컨테이너 실행 모델을 충분히 이해하지 못했기 때문이다.
이번 편에서는
Parca를 Kubernetes 환경에서 해석하기 위해
반드시 알아야 할 3가지 축을 정리한다.
- PID Namespace
- 다른 Namespace들
- cgroup
1️⃣ 컨테이너 환경에서 profiling이 어려운 이유


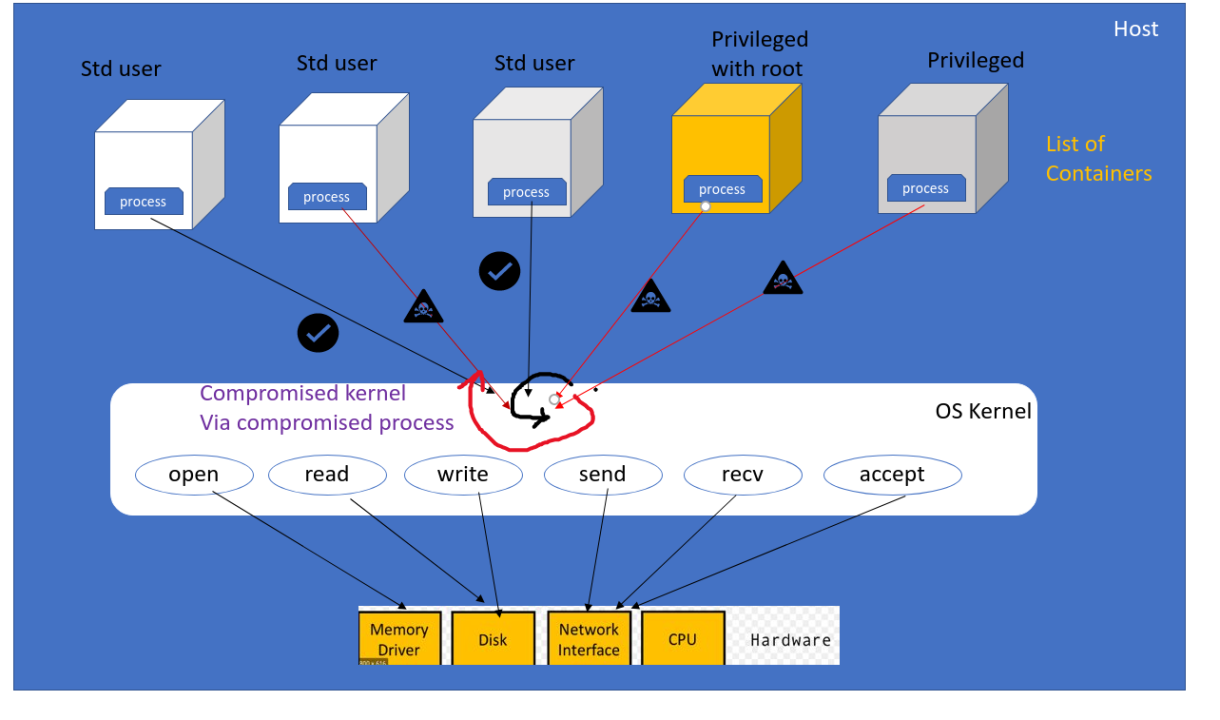
컨테이너는 “가상 머신”이 아니다.
- 커널은 호스트와 공유
- 프로세스는 Namespace로 분리
- 자원 사용량은 cgroup으로 제한
즉,
“하나의 커널 위에
여러 개의 논리적 세계가 겹쳐 있다.”
Parca는 이 겹침을 그대로 본다.
2️⃣ PID Namespace 관점에서의 Parca
컨테이너의 PID 1은 진짜 1이 아니다
컨테이너 안에서 보면:
$ ps -ef
PID 1 my-app
하지만 노드에서 보면:
$ ps -ef | grep my-app
PID 34721 my-app
- 컨테이너 내부: PID namespace 기준
- 노드/커널: 호스트 PID 기준
Parca는 어느 쪽을 보는가?
Parca는 커널이 보는 PID를 기준으로 샘플링한다.
즉:
- Flamegraph에 보이는 PID = 호스트 PID
- 컨테이너 내부 PID와 일치하지 않는 것이 정상
실무에서의 오해 포인트
❌ “왜 PID 1이 안 보이지?”
⭕ “PID 1은 컨테이너 namespace 안의 논리적 번호다”
Parca는 컨테이너 환상을 벗겨낸 상태를 보여준다.
3️⃣ Namespace 관점: 격리는 “완전하지 않다”
컨테이너는 여러 namespace로 격리된다.
- PID
- Mount
- Network
- IPC
- UTS
- User
하지만 중요한 사실 하나:
CPU 실행은 namespace로 격리되지 않는다.
- 스케줄링
- syscall
- interrupt
- context switch
이 모든 것은 호스트 커널 전역이다.
Flamegraph에 커널 함수가 많은 이유

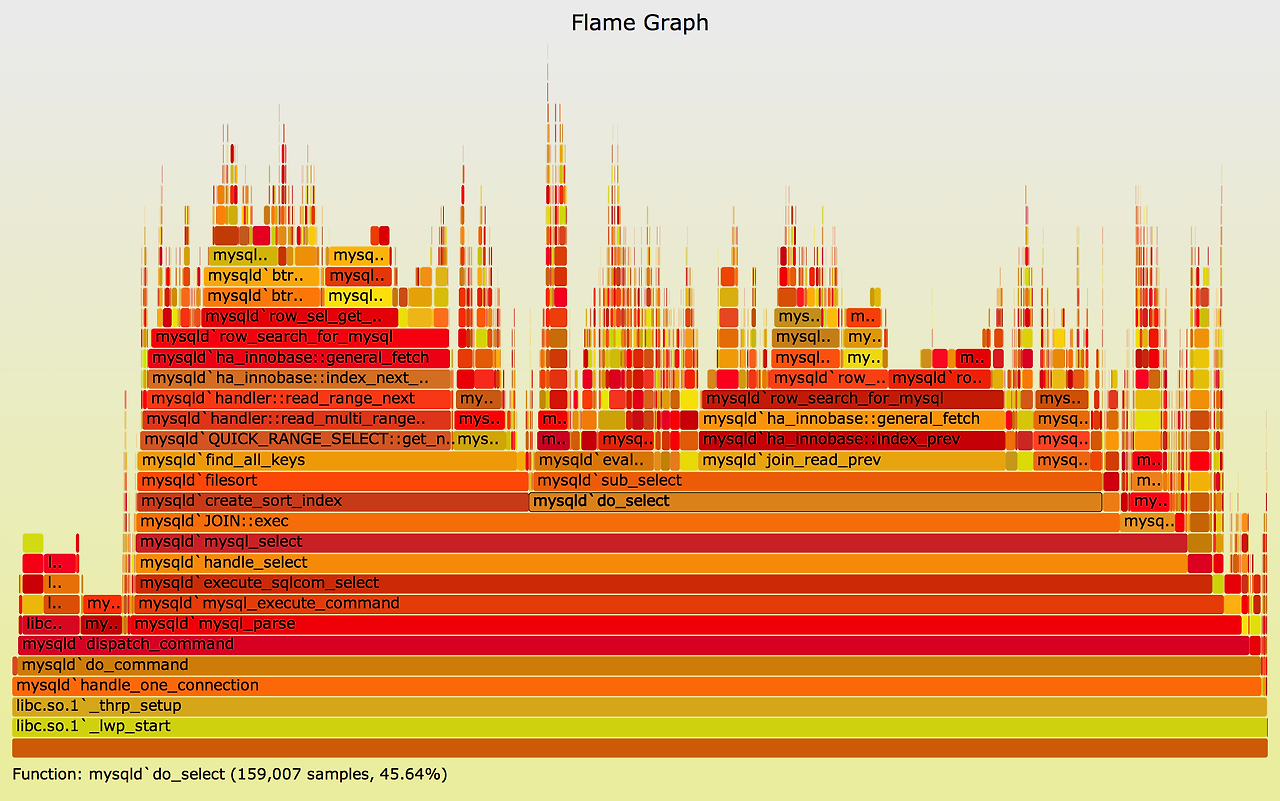
Kubernetes 환경에서 Parca Flamegraph를 보면
다음이 자주 보인다.
__schedule()
do_syscall_64()
futex_wait()
이건 이상이 아니다.
- 컨테이너 수 증가
- 스레드 수 증가
- 락 / I/O 증가
→ 커널 비중 자연 증가
4️⃣ cgroup: 컨테이너를 구분하는 핵심 단서
여기서 Parca가 빛을 발한다.
컨테이너 구분의 핵심은 PID가 아니라 cgroup이다.
Parca는 cgroup 정보를 수집한다
parca-agent는 샘플링 시점에:
- 현재 task의 cgroup 정보
- container / pod label
을 함께 태깅한다.
이 덕분에 Parca Server에서는:
- pod 단위
- container 단위
- namespace 단위
로 Flamegraph를 필터링할 수 있다.
Kubernetes에서의 필터링 예
namespace = "production"
pod = "api-server-7f9c8d"
container = "app"
→ 이 조건으로 보면
다른 컨테이너의 CPU 경로는 완전히 제거된다.
5️⃣ “PID 1”이 Flamegraph에 보일 때의 의미
Kubernetes 환경에서 흔히 보이는 장면이다.
PID 1
└─ pause
이건 오류가 아니다.
pause 컨테이너의 역할
- pod의 네트워크 namespace 유지
- 실제 workload 없음
- 하지만 namespace anchor 역할
Parca Flamegraph에서 pause가 보인다면:
- CPU를 썼다는 의미 ❌
- namespace 경로상 등장했다는 의미 ⭕
6️⃣ DaemonSet으로 배포하는 이유


Parca Agent는 반드시 노드 단위로 배포해야 한다.
이유
- eBPF는 노드 커널에 attach
- 컨테이너 하나에만 붙이면:
- 다른 컨테이너의 CPU 실행 경로 누락
- 커널 스택 왜곡
DaemonSet 예시(yaml)
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: parca-agent
spec:
template:
spec:
hostPID: true
containers:
- name: parca-agent
image: ghcr.io/parca-dev/parca-agent
securityContext:
privileged: true
hostPID는 선택이 아니라 필수에 가깝다
7️⃣ Kubernetes 환경에서 Flamegraph 해석 요령
- 반드시 지켜야 할 규칙
- 필터부터 걸고 본다
- namespace / pod / container
- PID 번호에 집착하지 않는다
- 커널 함수 비중을 정상으로 받아들인다
- 단일 Flamegraph로 결론 내리지 않는다
자주 하는 잘못된 해석❌ “PID가 이상하니 Parca가 틀렸다”
⭕ “PID namespace를 이해해야 한다”
8️⃣ 이 편의 핵심 요약
- Parca는 컨테이너가 아니라 커널을 본다
- 컨테이너 구분은 PID가 아니라 cgroup
- Kubernetes에서 Parca는:
- 더 강력해지고
- 동시에 더 오해받기 쉽다
Parca는 그 추상화를 벗긴다.
다음 편 예고- 커널 버전 차이를 어떻게 극복하는가
- BTF는 무엇인가
- 왜 운영 환경에서 중요한가
다음 편 - 필터부터 걸고 본다
- 8편. CO-RE와 Parca – 커널 의존성 문제는 어떻게 해결되는가
- 다음 편에서는
Parca의 또 다른 핵심 기술인 CO-RE를 다룬다. - ❌ “커널 함수가 많으니 커널 문제다”
⭕ “컨테이너 수 증가로 커널 경로가 늘었다”
'Parca' 카테고리의 다른 글
| 9편. Parca 도입 시 현실적인 고려사항– 운영, 보안, 성능 관점 (0) | 2025.12.20 |
|---|---|
| 8편. CO-RE와 Parca – 커널 의존성 문제는 어떻게 해결되는가 (0) | 2025.12.20 |
| 6편. 실전 사례 ① – CPU 사용률은 정상인데, 성능은 느린 이유 (0) | 2025.12.18 |
| 5편. Flamegraph 제대로 읽기– Parca UI 해석 가이드 (0) | 2025.12.18 |
| 4편. Parca와 기존 APM / 모니터링 에이전트 비교– 무엇이 같고, 무엇이 다른가 (0) | 2025.12.18 |