실전 사례 ①
CPU 사용률은 정상인데, 성능은 느린 이유
운영 중인 서버에서 다음과 같은 리포트를 받았다고 가정해 보자.
- CPU 사용률: 평균 40~50%
- Load Average: 정상
- 메모리 여유 충분
- APM: 주요 API 응답 시간 “정상 범위”
- 사용자 체감: “전체적으로 느림”
이 상황은 의외로 매우 흔하다.
그리고 가장 골치 아픈 유형이기도 하다.
1. 문제의 핵심: “정상 지표”의 함정
전통적 모니터링 지표
CPU: 45%
Memory: 62%
Disk IO: 낮음
Network: 정상→ 문제 없어 보인다.
APM 지표
/api/search 평균 110ms
/api/order 평균 180ms
에러율 0%
→ 역시 문제 없어 보인다.
이 단계에서 흔히 나오는 결론은 이것이다.
“일시적인 네트워크 문제였나 봅니다.”
하지만 사용자는 여전히 느리다고 말한다.
2. 문제를 다시 정의하기
여기서 질문을 바꿔야 한다.
❌ “CPU가 얼마나 쓰이고 있는가?”
⭕ “CPU가 실제로 무엇을 하고 있는가?”
이 질문은
기존 메트릭이나 APM으로는 답할 수 없다.
이 지점에서 Parca를 투입한다.
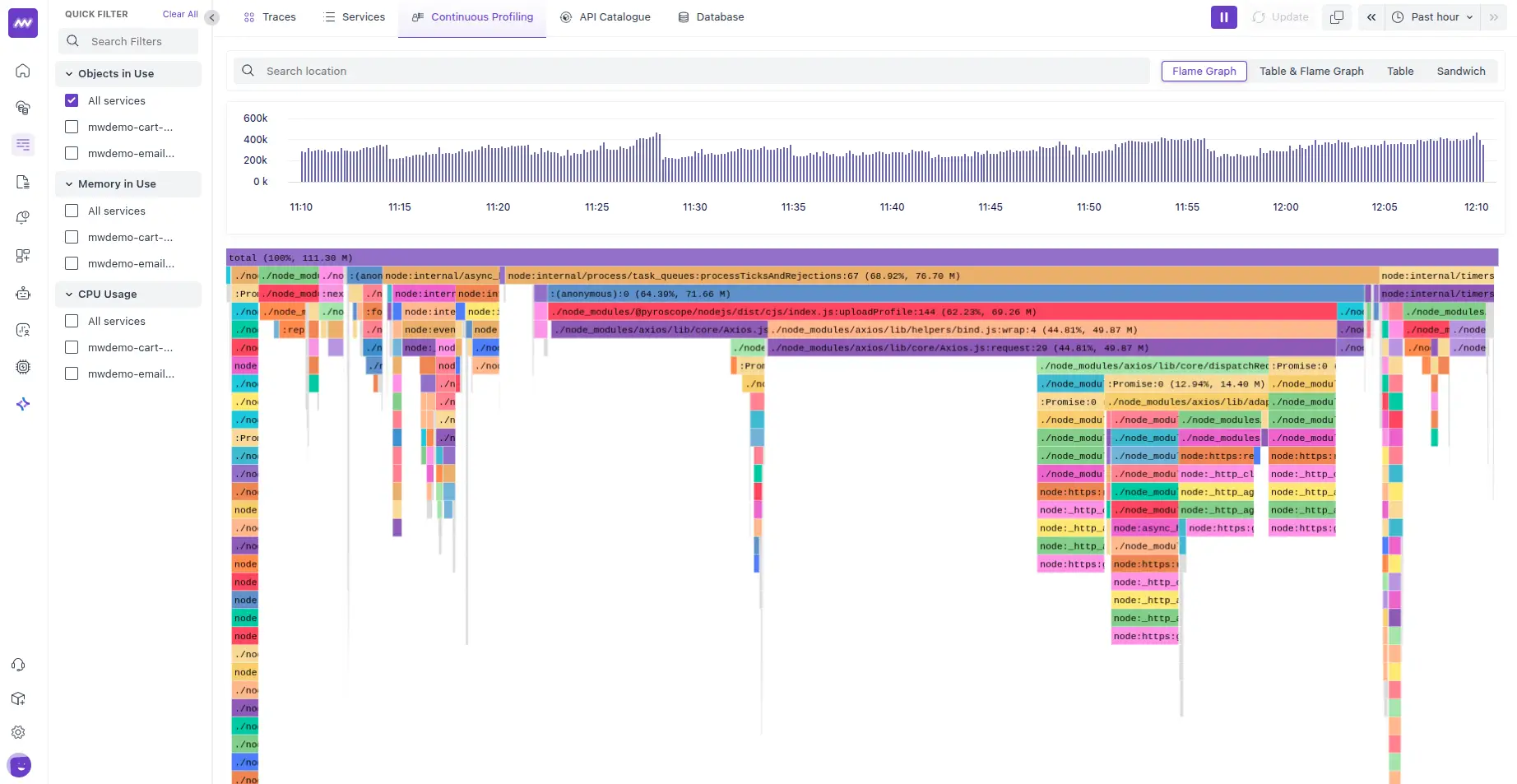
3. Parca로 본 Flamegraph 첫 화면



Flamegraph를 처음 보면 이런 특징이 보인다.
- 전체 폭은 넓지 않다 (CPU 사용률이 낮으니)
- 그런데 커널 함수 비중이 유난히 크다
- __schedule() / futex_wait() 가 반복 등장
이 화면이 말해주는 메시지는 명확하다.
CPU는 계산을 안 하고,
기다리는 데 시간을 쓰고 있다.
4. Flamegraph 해석 단계별 사고 과정
1단계: 바닥부터 보기
바닥(entry)에 다음과 같은 경로가 반복된다.
sys_futex
└─ futex_wait
└─ __schedule이 패턴은 거의 공식처럼 해석할 수 있다.
“스레드가 락을 기다리며 잠들었다.”
2단계: 유저 코드와의 연결점 찾기
커널 스택 위쪽을 따라 올라가면
유저 공간 함수가 보이기 시작한다.
pthread_mutex_lock
└─ cache_update()
└─ handle_request()이제 그림이 그려진다.
- 요청 처리 중
- 특정 cache_update 로직에서
- mutex lock 대기 발생
- 스레드가 잠들며 context switch
5. 왜 CPU 사용률은 낮았는가?
이 질문이 핵심이다.
CPU 사용률이 낮다는 것은:
- CPU가 놀고 있다 ❌
- 실행할 준비가 된 스레드가 없다 ⭕
락 대기로 스레드들이 잠들어 있으면
CPU는 놀게 된다.
즉,
CPU 사용률은 낮지만
시스템은 느릴 수 있다.
6. APM으로는 왜 보이지 않았을까?
APM의 관점은 “요청”이다.
- 요청 시작
- DB 쿼리
- 비즈니스 로직
- 응답 반환
락 대기는 보통 이렇게 보인다.
Business logic: 180msAPM은 말하지 않는다.
- 그 180ms 중
- 몇 ms가 락 대기인지
- 몇 ms가 실제 계산인지
Parca는 이 공백을 메운다.
7. 코드 레벨에서의 문제 예시
문제의 원인이 된 코드를 단순화하면 다음과 같았다.
pthread_mutex_lock(&cache_lock);
/* cache 갱신 */
update_global_cache(req);
pthread_mutex_unlock(&cache_lock);
문제는 이 코드가:
- 모든 요청 경로에서
- 동일한 전역 락을 사용
- cache update 빈도가 높음
결과적으로:
- 요청 수 증가
- 락 경합 증가
- 스레드 대기 증가
- 체감 성능 저하
8. Parca가 아니었다면?
이 문제를 Parca 없이 찾으려면:
- perf 수동 실행
- 문제 시점 재현 시도
- 운 좋게 같은 상황 발생
- 커널 스택 해석
운영 환경에서는 거의 불가능에 가깝다.
Parca는 이미 문제 시점의 흔적을
저장해 두고 있었다.
9. 개선 후 Diff Flamegraph
개선은 단순했다.
- 전역 mutex 제거
- shard 기반 lock 분리
- cache update 최소화
배포 전/후 Diff Flamegraph 비교
Parca의 Diff Flamegraph는
두 시점(또는 두 배포 버전)의 CPU 실행 경로 변화를 색상으로 직관적으로 보여준다.
- 빨간색: CPU 사용이 증가한 경로
- 파란색: CPU 사용이 감소한 경로
- 회색/중립: 큰 변화 없음


배포 전 (Before)
- __schedule()
- futex_wait()
- pthread_mutex_lock()
경로가 넓고 반복적으로 등장
→ 스레드가 자주 잠들고 깨어남
→ 락 경합 + 스케줄링 오버헤드
배포 후 (After)
- 커널 스케줄링 경로 파란색으로 감소
- 유저 함수 실행 경로 상대적으로 증가
- Flamegraph의 “톱니형 분기” 감소
이는 다음을 의미한다.
CPU가 기다리는 시간은 줄고,
실제 일을 하는 시간은 늘어났다.
이 Diff 화면이 주는 결정적 가치
이 한 장의 Diff Flamegraph만으로도 다음을 동시에 설명할 수 있다.
- 왜 체감 성능이 개선되었는지
- 왜 CPU 사용률이 크게 변하지 않았는지
- 왜 APM 지표는 큰 변화가 없었는지
즉,
“성능 개선이 실제로 CPU 실행 경로를 바꿨다”
는 증거가 된다.
10. 이 사례가 주는 교훈
이 사례의 핵심은 이것이다.
- CPU 사용률은 결과일 뿐
- 원인은 실행 경로에 있다
- APM과 메트릭은 충분조건이 아니다
Parca는 다음 질문에 답해준다.
“CPU 시간이 왜 그렇게 쓰였는가?”
체크리스트: 비슷한 증상을 만났다면
- CPU 사용률은 정상인데 느리다
- APM은 정상인데 체감이 나쁘다
- 요청 수가 늘수록 더 느려진다
- 컨텍스트 스위치가 많아 보인다
→ Parca로 커널 스택부터 확인하라
이 편의 결론
“느리다”는 말은 감정이지만,
Flamegraph는 증거다.
Parca는
설명하기 어려운 성능 문제를
말로 설명 가능하게 만들어 주는 도구다.
다음 편 예고
다음 편에서는
이번보다 한 단계 더 들어가서,
- 컨테이너 환경
- Kubernetes
- PID / namespace / cgroup
에서 Parca를 어떻게 해석해야 하는지를 다룬다.
다음 편
7편. 컨테이너·Kubernetes 환경에서의 Parca – PID, Namespace, cgroup 관점
'Parca' 카테고리의 다른 글
| 8편. CO-RE와 Parca – 커널 의존성 문제는 어떻게 해결되는가 (0) | 2025.12.20 |
|---|---|
| 7편. 컨테이너·Kubernetes 환경에서의 Parca– PID, Namespace, cgroup 관점 (0) | 2025.12.20 |
| 5편. Flamegraph 제대로 읽기– Parca UI 해석 가이드 (0) | 2025.12.18 |
| 4편. Parca와 기존 APM / 모니터링 에이전트 비교– 무엇이 같고, 무엇이 다른가 (0) | 2025.12.18 |
| 3편. parca-agent 내부 구조 분석 – eBPF 기반 수집 메커니즘 (0) | 2025.12.18 |