Flamegraph 제대로 읽기
Parca UI 해석 가이드
Parca를 처음 실행하면 대부분 이런 반응을 보인다.
“그래프는 나오는데…
이걸 어떻게 해석해야 하지?”
Flamegraph는 직관적인 듯 보이지만,
실제로는 매우 쉽게 오해되는 시각화다.
이번 편의 목표는 단 하나다.
Flamegraph를 ‘그림’이 아니라
‘성능 설명 도구’로 읽게 만드는 것
Flamegraph는 무엇을 보여주는가 (한 문장 정의)
Flamegraph는
CPU 시간이 어떤 함수 호출 경로에서
얼마나 사용되었는지를 보여준다.
여기서 핵심 단어는 세 가지다.
- CPU 시간
- 함수 호출 경로 (call stack)
- 누적 분포

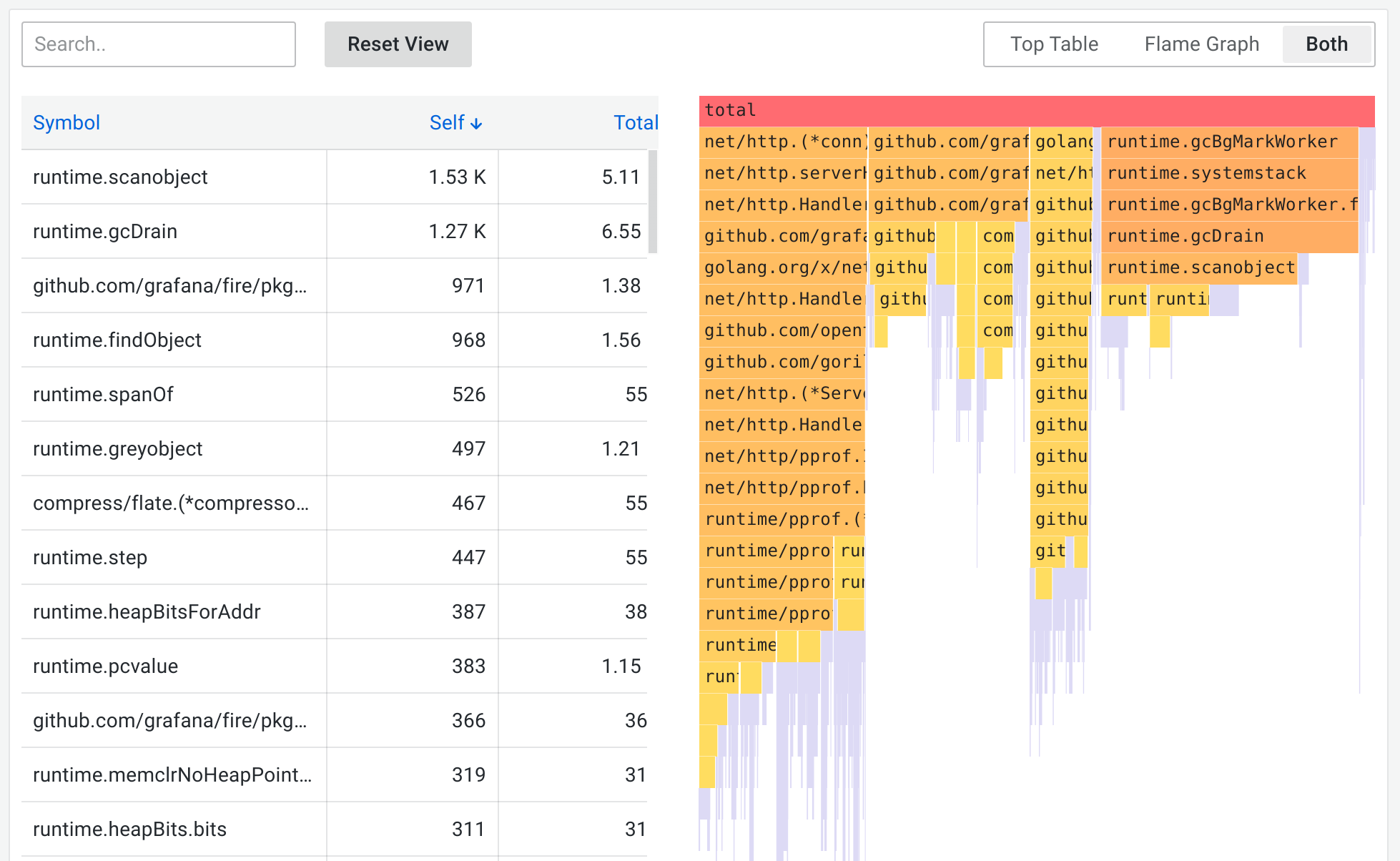

Parca UI에서 보는 Flamegraph는 다음과 같은 규칙을 가진다.
X축: 시간 비율 (가로 폭)
- 가로 폭이 넓을수록
→ CPU 시간을 많이 사용 - 좌우 위치 자체에는 의미 없음
- 폭만 의미가 있다
Y축: 호출 깊이 (세로)
- 아래 → 위로 갈수록
→ 더 깊은 함수 호출 - 맨 아래는 진입점 (entry)
- 맨 위는 실제 실행 지점 (hot code)
가장 흔한 오해 ①
“위에 있는 함수가 범인이다?”
❌ 틀렸다.
Flamegraph에서 위에 있다는 사실 자체는 중요하지 않다.
중요한 것은:
얼마나 넓은 경로의 ‘끝’에 있는가
잘못된 해석 예
맨 위에 custom_hash_lookup() 이 있음
→ 이 함수가 문제다이 해석은 위험하다.
올바른 질문은 이것이다.
“custom_hash_lookup() 이
전체 CPU 시간 중 몇 %의 경로에 포함되는가?”
Inclusive Cost vs Exclusive Cost
Flamegraph를 이해하는 핵심 개념이다.
Inclusive Cost (포함 비용)
- 어떤 함수 +
그 함수가 호출한 모든 하위 함수 - Flamegraph의 가로 폭
Exclusive Cost (자기 비용)
- 해당 함수 자체 실행 시간
- Flamegraph에서는 직접 보이지 않음
- 툴팁이나 diff로 해석
예시 사고 흐름
A()
└─ B()
└─ C()
- C가 느리면
→ A, B, C 모두 넓게 보인다 - A가 넓다고 해서
→ A가 문제인 것은 아니다
Flamegraph를 읽는 올바른 순서
많은 사람들이 위에서 아래로 본다.
하지만 정답은 반대다.
1단계: 바닥부터 본다
- 맨 아래 함수는 무엇인가?
- entry point는 어디인가?
- syscall?
- 런타임?
- application main loop?
2단계: 넓은 “기둥”을 찾는다
- 특정 함수 위로
지속적으로 넓은 폭이 유지되는가 - 중간에 폭이 갑자기 좁아지지 않는가
3단계: 분기 지점을 본다
- 한 함수에서
여러 갈래로 나뉘는가? - 특정 분기만 유난히 넓은가?
이 지점이 의사결정 포인트다.
커널 스택 vs 유저 스택 구분하기
Parca Flamegraph의 강력한 점은
커널과 유저 스택을 함께 보여준다는 것이다.
커널 함수가 넓게 보이는 경우
__schedule()
mutex_lock()
futex_wait()
의미하는 바는 보통 다음 중 하나다.
- 락 경합
- 스레드 대기
- 스케줄링 지연
- 과도한 context switch
이 경우 애플리케이션 코드만 보면 답이 없다.
유저 함수가 넓게 보이는 경우
parse_json()
custom_hash_lookup()
compress_block()
이 경우는 비교적 단순하다.
- 알고리즘 문제
- 데이터 구조 문제
- 캐시 미스
- 불필요한 반복
실전 예제 ①
“CPU 사용률은 높은데, 일은 안 한다”


Flamegraph 특징
- __schedule() 폭이 매우 넓음
- 여러 경로에서 반복 등장
- 유저 함수는 상대적으로 얇음
해석
CPU는 바쁘지만
실제 계산은 거의 하지 않는다
→ 락/동기화 문제
APM으로는 거의 잡히지 않는 유형이다.
실전 예제 ②
“특정 배포 이후 느려졌다”
이럴 때 Parca의 진가는 **비교(diff)**에서 나온다.
Diff Flamegraph의 의미
- 빨간색: 증가한 CPU 경로
- 파란색: 감소한 CPU 경로
custom_hash_lookup() +12%
old_cache_lookup() -8%이 한 화면으로
**성능 회귀(regression)**를 설명할 수 있다.
Flamegraph는 “원인 후보 지도”다
중요한 관점 하나를 강조하자.
Flamegraph는
“정답”을 알려주지 않는다
“의심 지점”을 알려준다
- 왜 넓은가?
- 왜 이 경로가 많아졌는가?
- 왜 이전에는 없었는가?
이 질문은
사람이 해야 한다.
Parca UI에서 꼭 봐야 할 포인트
- 시간 범위를 좁혀서 본다
- 배포 시점 전/후 비교
- label(node, pod, container) 필터 적극 활용
- 하나의 Flamegraph로 결론 내리지 않는다
자주 하는 치명적 실수 정리
- ❌ “위에 있는 함수 = 범인”
- ❌ “한 장의 Flamegraph로 결론”
- ❌ 커널 스택 무시
- ❌ 폭이 좁은데 이름만 보고 의심
이 편의 결론
Flamegraph를 제대로 읽을 수 있게 되면:
- CPU 사용률 숫자는 의미를 잃는다
- “느리다”는 말을 설명할 수 있게 된다
- 성능 문제 논의가 감정이 아니라 근거가 된다
Parca의 가치는
Flamegraph를 이해하는 순간부터 시작된다.
다음 편 예고
다음 편에서는
Flamegraph를 실제 장애·성능 이슈에 적용하는
실전 사례 중심 편으로 넘어간다.
다음 편
6편. 실전 사례 ① – CPU 사용률은 정상인데, 성능은 느린 이유
'Parca' 카테고리의 다른 글
| 7편. 컨테이너·Kubernetes 환경에서의 Parca– PID, Namespace, cgroup 관점 (0) | 2025.12.20 |
|---|---|
| 6편. 실전 사례 ① – CPU 사용률은 정상인데, 성능은 느린 이유 (0) | 2025.12.18 |
| 4편. Parca와 기존 APM / 모니터링 에이전트 비교– 무엇이 같고, 무엇이 다른가 (0) | 2025.12.18 |
| 3편. parca-agent 내부 구조 분석 – eBPF 기반 수집 메커니즘 (0) | 2025.12.18 |
| 2편. Parca 아키텍처 한눈에 보기 – Server, Agent, Storage 구조 (0) | 2025.12.18 |